Webscraping with Symfony
By Rutger2 at nl.wikipedia, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=9693749
Web-scraping is ugly, but sometimes it may become necessary, because services don’t expose an API to retrieve data. Basically web-scraping is a mechanism to programatically open a website and grab the contents in order to using it for own purposes.
The mission
In one of our sites, we are using the HTML output of a not-that-hip-anymore-database allegro. The data has already been migrated to another service, but somehow we needed to get the allegro data to generate a TYPO3 Extension with a list and a detail view.
As the allegro database (the service is called HANS, an acronym, because librarians love acronyms)provides us some HTML code as a list and with a link to a detail view and also a link to the new System, I decided to
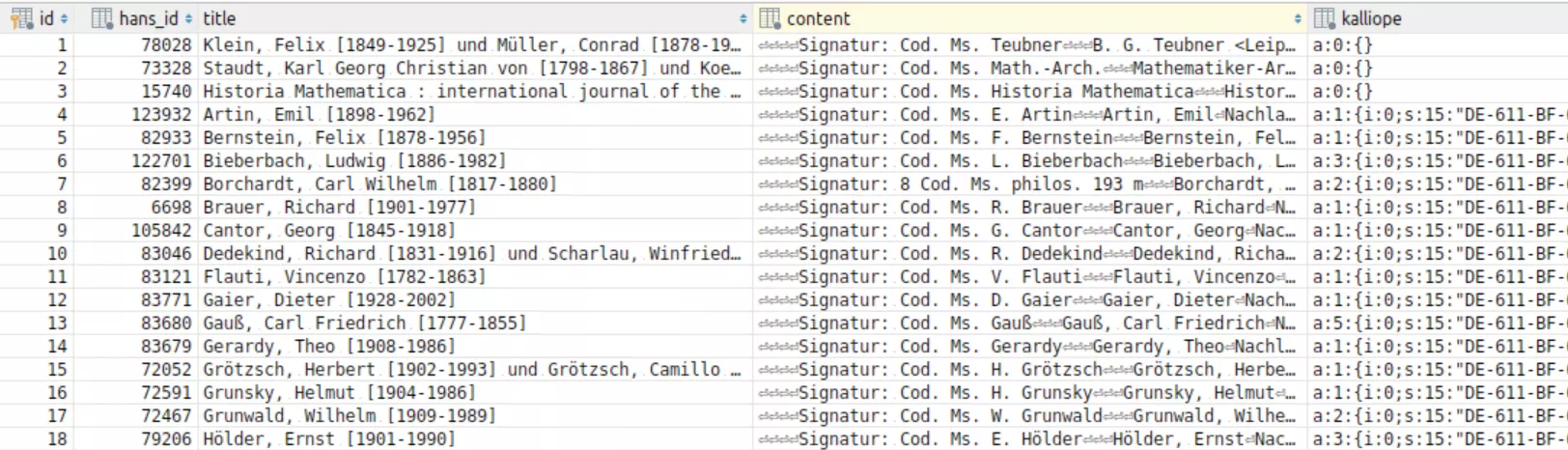
build a database structure with the fields id (auto generated, auto incremented), hans_id (integer), title from the list view as string, content that contains the contents
from the detail page as text field and finally kalliope as array, that contains the identifier in the new database Kalliope.
The implementation
I set up a small Symfony Console application and used the DOM Crawler Component to retrieve the data and Goutte to do the HTTP requests.
The data is stored in a SQLite Database, as there is no need for more sophisticated solutions, such as MySQL or PostgreSQL.
The application starts like that:
$client = new Client();
$crawler = $client->request('GET', $this->listViewUrl);
$crawler = $crawler->filter('OL > LI');
foreach ($crawler as $domElement) {
$hans = new Hans();
$hansId = $this->getHansId($domElement->firstChild->getAttribute('href'));
$hans
->setHansId($hansId)
->setTitle($domElement->textContent)
->setContent($this->getDetails($hansId))
->setKalliope($this->getKalliopeIds($hansId));
$this->entityManager->persist($hans);
$this->entityManager->flush();
The application is run either locally with ./bin/console app:import or (as usually) with Docker.
Building: docker build -t hansexport . Running: docker run -it --rm -e "LIST_VIEW_URL=https://example.com" -e "DETAIL_VIEW_URL=https://example.com/detail" hansexport
It starts a GET request to the list view, and calls further functions to get the desired data.
The list data looks like that:
<OL>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=83046">Dedekind, Richard [1831-1916] und Scharlau, Winfried [1940-]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=83121">Flauti, Vincenzo [1782-1863]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=83771">Gaier, Dieter [1928-2002]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=83680">Gauß, Carl Friedrich [1777-1855]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=83679">Gerardy, Theo [1908-1986]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=72052">Grötzsch, Herbert [1902-1993] und Grötzsch, Camillo [1874-]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=72591">Grunsky, Helmut [1904-1986]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=72467">Grunwald, Wilhelm [1909-1989]</A></LI>
<LI><A HREF="/cgi-bin/ssgfi/zdmn.pl?t_show=x&reccheck=79206">Hölder, Ernst [1901-1990]</A></LI>
…
</OL>
The values are assigned to a Hans POPO
and persisted in the database afterwards. Dumping the database contents enables the further use for our TYPO3 application.
There is no magic included, and the complete code for that application can be found on GitHub.
