Static Infrastructure Status with Jekyll and GitHub Pages
Technology fails – at least sometimes.
This is particularly true for a modern distributed research infrastructure, such as DARIAH-DE.
For the operation of this infrastructure, we have implemented a monitoring solution with Icinga.
This enables us to be informed about problems and react quickly.
In an ideal state, our world looks like this:
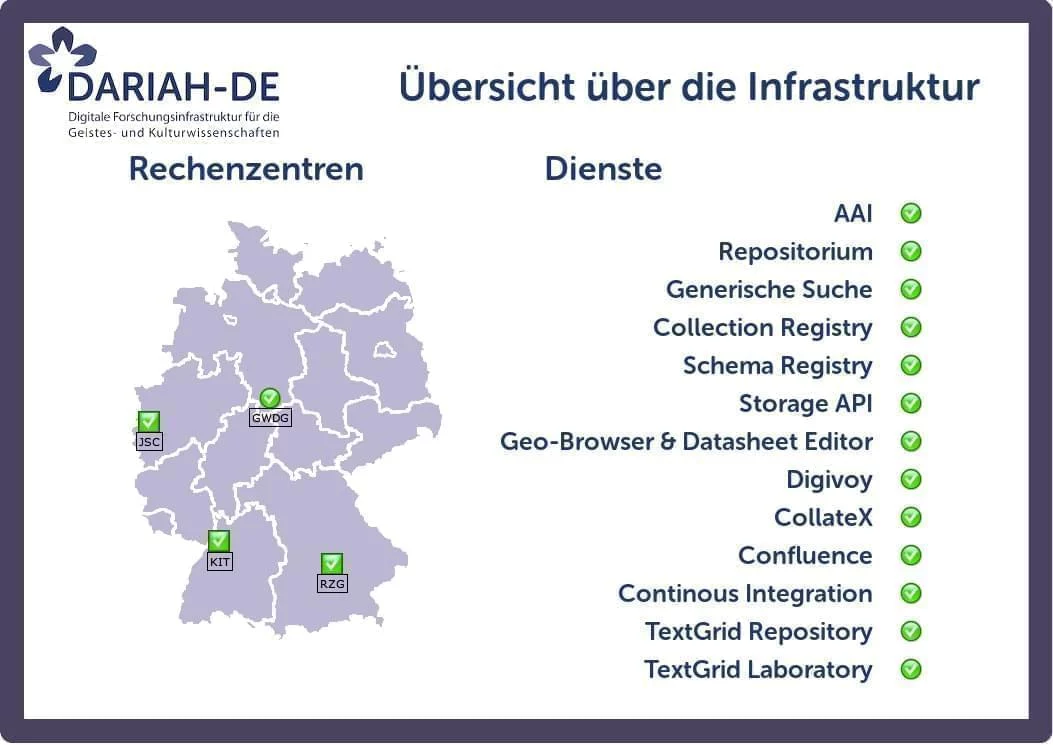
As well as this works, the problems we face are manifold:
- Users don’t know if someone is already working on a red icon here.
- This map shows only the current state, but sometimes maintenances must be announced in advance.
- The monitoring itself is not entirely independent from the infrastructure.
Usually, our engineers are quick in identifying problems and fixing them. But if users start querying them about the status of the issue they are working on, it won’t get fixed quicker.
So we decided to build an independent and manually curated status page.
GitHub status page
The first approach, was to have a static HTML file on GitHub pages with current information. The advantages of this approach are:
- The status page is entirely independent from our infrastructure and reasonably reliant.
- Security-wise, static pages are probably the best you can do.
- Authentication and authorisation are handled entirely outside our infrastructure. But since it’s GitHub, we feel reasonably safe to assume that everyone will have their credentials at hand even in a stressful event such as a datacenter outage.
This page was well-received by users and is now checked regularly by our power users in case of problems, instead of picking up the phone immediately.
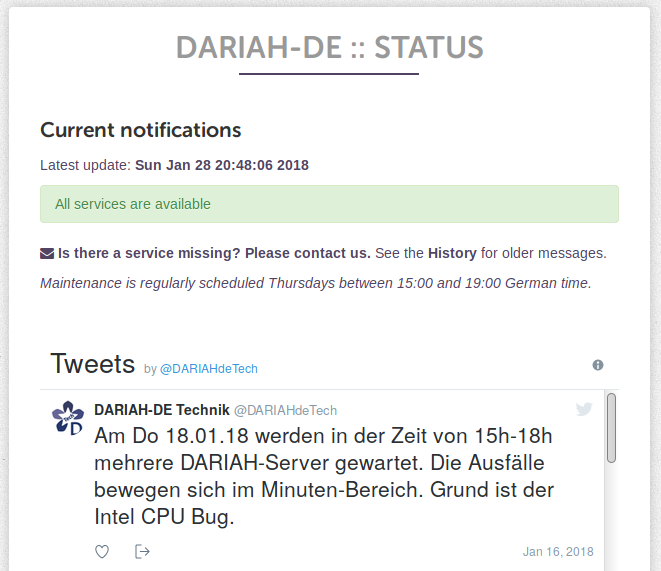
However, as the infrastructure grows, the number of dependencies increases and sometimes it is hard to list all services affected by a single outage.
Now powered by Jekyll
We decided to include the service dependencies directly into the GitHub page by utilising Jekyll’s Collections.
The services, middlewares and infrastructure components are now modelled in yaml datasets.
title: 'Example Service'
dependencies:
- '/infrastructure/storagesystem'
- '/servers/mymachine'
So in case of emergencies, we can add the actually broken parts to a Jekyll data file.
- title: 'The storage is full!'
description: "Don't worry, we ordered a few new hard drives."
date_start: '2018-02-12 11:01'
affected:
- '/infrastructure/storagesystem'
Then, using recursive liquid templates, we get a list of all of the affected services. In the above example, it would list at least Example Service but any other services that (indirectly) depends on storagesystem.

Of course, the same approach is possible for announcements of upcoming maintenances. For more details on the implementation, see the official documentation or the source code.
Status quo
The implementation is relatively new and not yet complete as of writing this article.
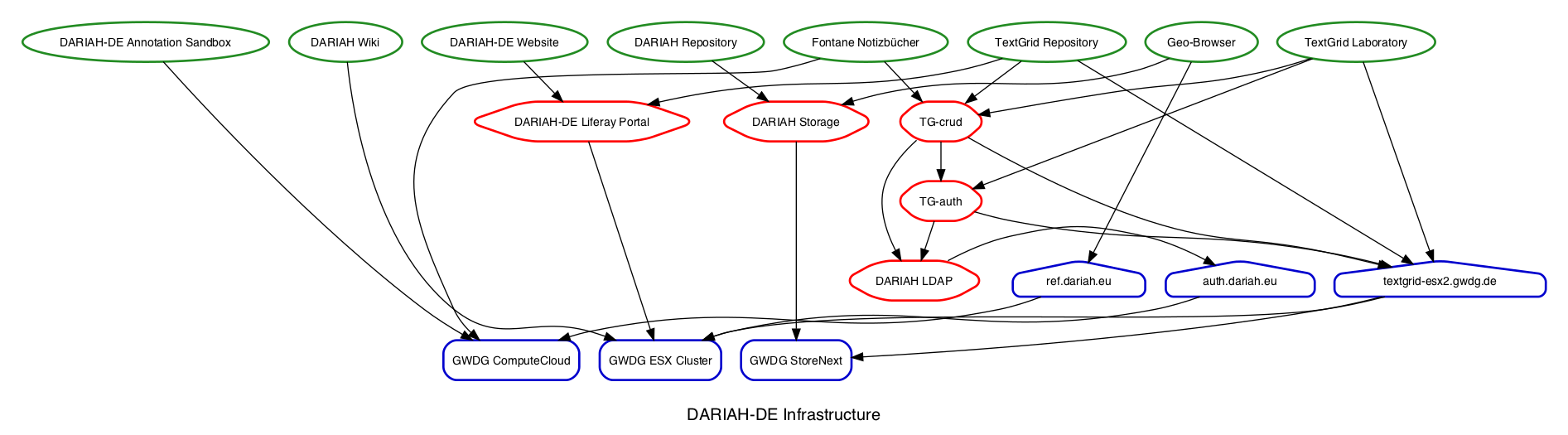 The graph shows the currently known dependencies.
Following a
The graph shows the currently known dependencies.
Following a git push, GitHub will generate the new page, as long as all dependencies can be resolved.
In parallel, Travis-CI will rebuild the dependency graph and compare it to the committed version using NetworkX.
Rebuilding the graph and populating the history is still manual, as this reduces complexity and future-proofs the tool for changes in the infrastructure that would break dependency resolution for historical data.
This solution was also the topic of a FOSDEM’18 lightning talk by the author:
