Baumbanken
Am 5. und 6. Dezember fand der „22. International Workshop on Treebanks and Linguistic Theories” statt, auf welchem auch das SUB-Kooperationsprojekt „Edition des Ugaritischen Poetischen Textkorpus” (EUPT) vorgestellt wurde. Doch was sind „Treebanks” (z. Dt. „Baumbanken”) überhaupt und welchen Nutzen haben sie für die Forschung und Entwicklung?
Der Call for Papers des Workshops definiert „Baumbanken” als „jegliche Paarung natürlicher Sprachdaten […] mit Annotationen zur linguistischen Struktur auf diversen Analyseebenen, darunter beispielsweise Morphophonologie, Syntax, Semantik und Diskurs”. Darunter können z. B. die Rohdaten für digitale Editionen fallen, die typischerweise im TEI-XML-Format gespeichert werden und Annotationen zur Textstruktur enthalten. Als Beispiel können wir hier einen Auszug der EUPT-Daten betrachten:
<unit>
<phr>
<w>ˀummatu</w>
<lb/>
<w>kirti</w>
<w><tei:damage>ˁa</tei:damage>ruwat</w>
</phr>
</unit>
Die XML-Rohdaten werden später in HTML konvertiert und als digitale Edition auf einer Webseite bereitgestellt.
Die Bezeichnung „Baumbank” für eine spezielle Form der (Sprach-)Datenbank rührt von der möglichen Darstellung der Daten als Baum (Out-Tree) her, d. h. eines gerichteten Graphen, in dem der Wurzelknoten keinen Elternknoten und jeder andere Knoten genau einen Elternknoten besitzt:
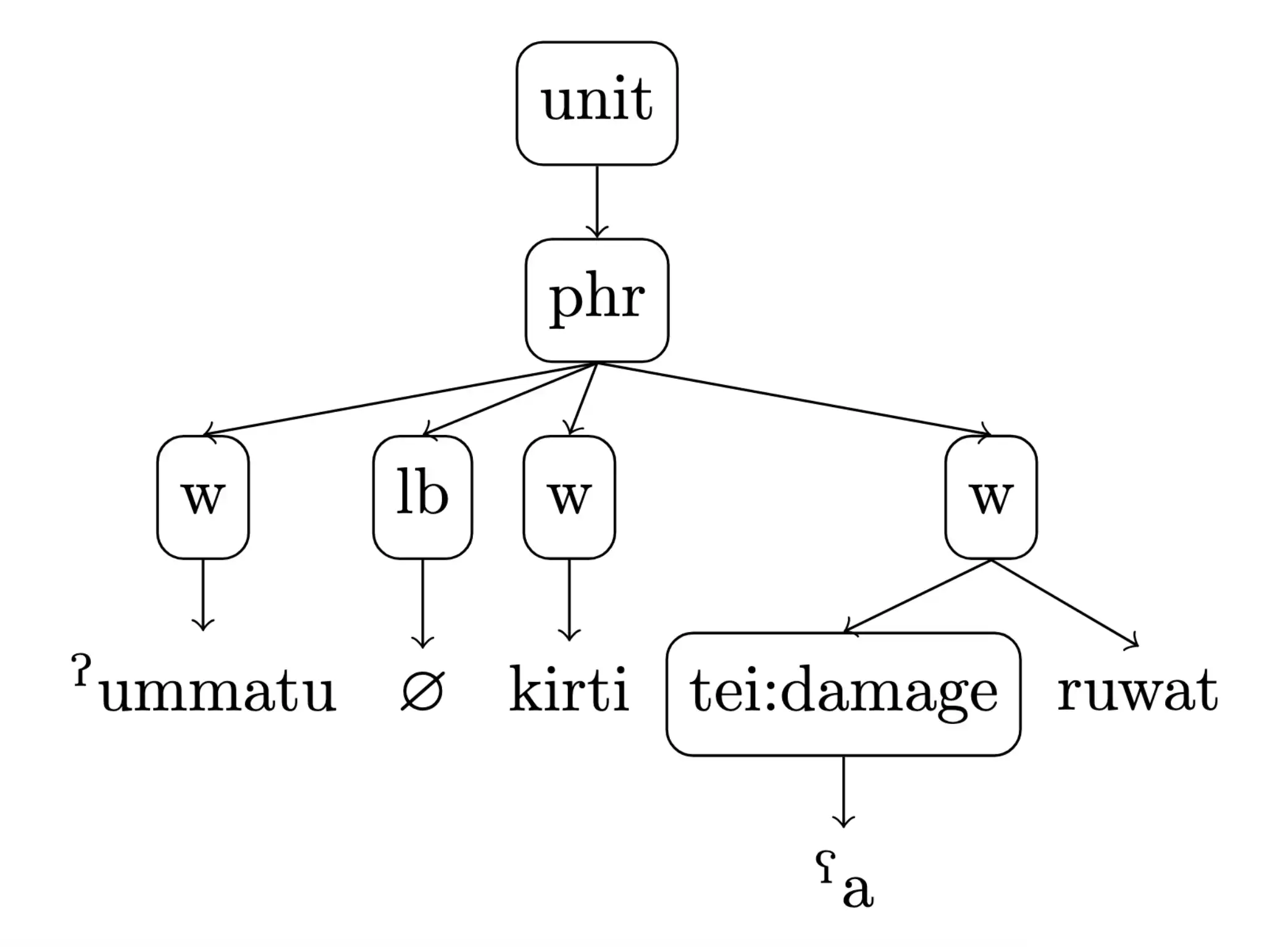
Die einzelnen Wörter des Beispiels bilden die Blattknoten des Baums. Die inneren Knoten (tei:damage, w, lb, phr) und der Wurzelknoten (unit) entsprechen strukturellen Kategorien: beschädigte(s) Zeichen, Wort, Zeilenumbruch, Phrase, (Teil-)Satz. Diese Art von Bäumen, die sich in Wort-Knoten und Struktur-Knoten aufteilen, bezeichnet man auch als „Phrasenstrukturbäume”.
Dem gegenüber stehen sogenannte „Dependenzbäume”, in denen es ausschließlich Wort-Knoten gibt. Ein weit verbreitetes Format für Dependenzbäume sind beispielsweise die Universal Dependencies (UD), mit denen die syntaktische Struktur eines Satzes erfasst werden kann. Zum Beispiel ist ˀummatu hier als das Subjekt (nsubj) von ˁaruwat annotiert:
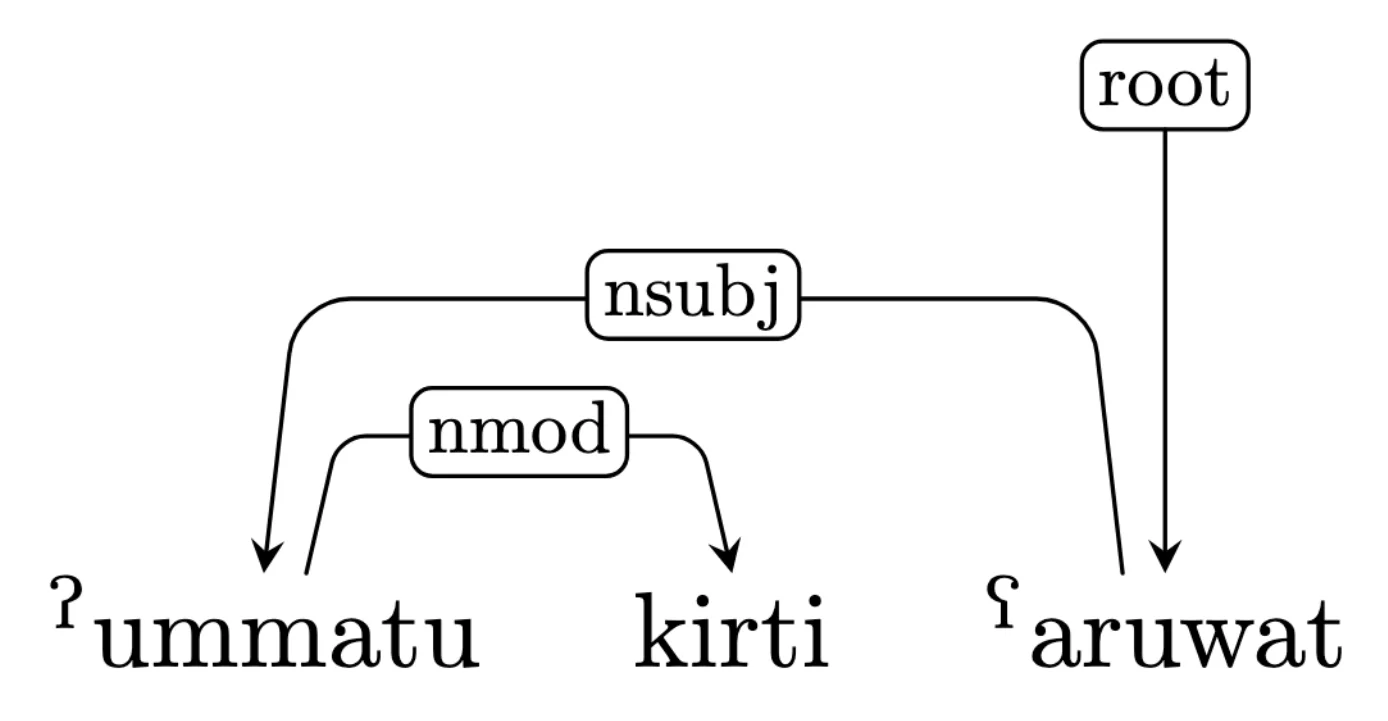
Dependenzbaumbanken werden in der maschinellen Sprachverarbeitung hauptsächlich genutzt, um Parser zu trainieren, die wiederum Dependenzbäume für neue Daten erstellen können. Beispielsweise enthält das von der SUB Göttingen im Rahmen von Text+ bereitgestellte Python-Paket „MONAPipe” einen Parser, der auf den deutschen UD-Baumbanken trainiert wurde. Darüber hinaus werden Dependenzbaumbanken oft in der (Computer-)Linguistik genutzt, um mittels statistischer Analysen Erkenntnisse über die strukturellen Eigenschaften von Sprachen zu gewinnen.
Baumstrukturen haben allerdings den Nachteil, dass bestimmte sprachliche Phänomene nicht oder nur umständlich abgebildet werden können. Daher befasst sich die Wissenschaft zunehmend mit der Entwicklung allgemeinerer Graphmodelle für die Erfassung von Sprachdaten und Annotationen (z. B. enhanced UD graphs). In EUPT werden für jeden Text nicht nur ein, sondern gleich drei (Unter-)Bäume für verschiedene Analyseebenen erstellt. Dazu kommen komplexe Annotationen wie Übersetzungen, philologische Kommentare und alternative Deutungen, die oft voneinander abhängen. Um die komplexen Verknüpfungen zwischen diesen verschiedenen Analyseebenen und Annotationen darzustellen, werden auch an der SUB Göttingen Graphdatenbanken erprobt.
Und hier geht’s zum Abstract unseres Workshop-Papers „A First Look at the Ugaritic Poetic Text Corpus”. Das Paper selbst wird demnächst hier (unter 2024) erscheinen.
